
微信扫一扫
关注公众号


从TDengine的开源说起技术选型
如果一艘快艇足够承载下你的所有货物到达彼岸,那么你不需要使用一艘轮船出行。产品设计和技术选型也是一样,我们经常会说:“我需要一个能够处理百万规模并发读写操作的,低延时,高可用的系统。” 如果按照这样的需求去设计系统,你可能得到的是一个设计复杂,代价昂贵的通用方案。但是如果仔细分析一下需求,你可能省略了需求背后的一些前提条件,比如真实的需求可能是这样的:“我需要一个能够处理百万规模的并发(只是理论峰值,平均情况小于10万并发)读写操作(读写比例1:9,只有追加写,没有修改操作)的低延时,高可用的(可以接受一定程度数据不一致性的)系统。” 那么你可能可以为这个特定的需求设计一个简单的,高效又低成本的系统。
做技术选型时,我们不会单纯的说A方案比B方案好,只是在解决特定的问题上,A方案比B方案更合适,选择了A方案的同时也意味着接受A方案里那些不如B方案的地方。在特定领域问题上的优化和定制方案往往能够取胜于解决更多领域问题的通用方案。最近涛思数据开源的TDengine也是这样一个针对专用领域的优化方案,TDengine的官方介绍如下:
“TDengine是一个针对物联网,车联网和工业物联网领域优化的开源大数据平台。除了是一个速度快10倍的时序数据库,它还提供了缓存,流式计算,消息队列和其他以减少开发和运维的复杂度和成本的功能。”

在TDengine的官网文档上我们可以了解到这是一个针对IOT领域数据特性优化的强大的大数据计算平台。最近花了一些时间去熟悉这个开源项目的文档和代码,聊聊在做IOT时序数据库这方面的技术选型时使用TDengine或者其他产品一些可能需要考虑的点。
版本的选择
TDengine提供了三个版本的产品:社区版,企业版以及云版本。 其中社区版是本次开源的 单机版本 ,根据官方的介绍社区版拥有TDengine的大部分核心功能,是 处理中小规模数据 的理想平台。 企业版 在社区版的基础上新增了 高可用、横行扩展 等集群功能,内置 异地副本复制 功能,可用性达运营商级服务等级,提供 更强大的运维管理工具 。 而云版本则为运行在AWS/阿里云上托管的企业版,按月付费省掉了你自己部署和系统运维的工作。 类似的,行业里另一个比较流行的开源时序数据库InfluxDB也同样提供了三个版本的选择: 开源的单机版,商业的集群版以及云版本,功能对比如下图。

开源协议的考虑
TDengine的社区版本 基于AGPL 3.0协议开源 。你可以免费的使用官方发布的TDengine社区版的二进制软件,但是如果你有修改或者基于TDengine衍生开发的软件产品,那么这部分软件也必须以AGPL协议的方式开源出来。AGPL协议是对GPL协议的一个补充,如果你没有分发衍生的软件产品(比如只是在服务端运行),按照GPL协议你不需要开源这部分,而按照AGPL协议你需要开源。
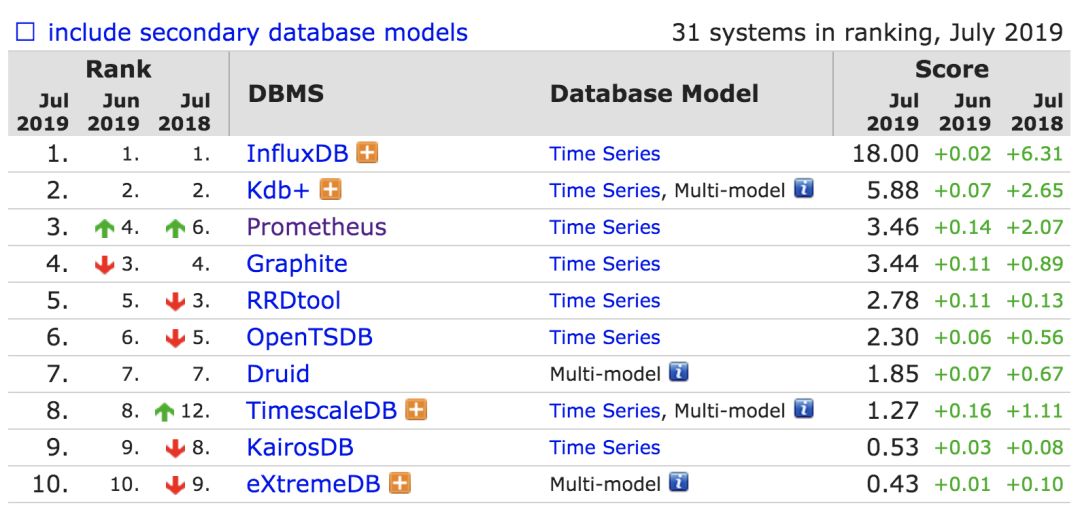
在db-engines.com上我们可以看到如下目前时序数据库的排行(TDengine尚未参与该排行)。其中前三名:InfluxDB采用MIT协议开源,Kdb+为商业协议,Prometheus是针对监控场景优化的时序数据库,采用Apache 2.0协议开源。InfluxDB早期曾经开源过其集群版本,2016年在探索其开源项目的商业模式时,选择了将集群版本的相关功能闭源作为企业版销售。业界一些公司如360基于InfluxDB的开源单机版本,开发了自己内部使用的闭源的集群版本QTSDB,同InfluxDB的企业版一样QTSDB通过shard group & shard进行数据分片,通过RAFT协议保障元数据的强一致性。
数据的删改支持
TDengine 不支持对已写入的数据进行删除或者修改 操作。TDengine的设计基于一个假设:数据由IOT的联网设备产生,时间序列的数据一旦产生便成为历史不再发生变化。数据写入后不再有删除和修改,使得TDengine大大简化了在数据存储上使用的数据结构,并且使得 一些聚合查询上可以通过预计算做到非常高效 。举个例子,可以在每个数据块上预存储该数据块上某个字段所有记录的最大值/最小值,当查询结果包含该块时,只需要读取这个预先算好的最值即可而不需要扫描整块数据。TDengine支持按时间过期的方式删除陈旧的历史数据避免无限量的数据增长。
类似的InfluxDB也是针对时序数据优化的数据库,这个优化导致了InfluxDB不是一个完全的CRUD数据库,更像是CRud,即优化读写数据的性能而限制一定自由度的修改和删除操作,但仍然支持:
-
你可以在同一张表里通过 插入一条一样时间戳的,拥有一样标签的记录来更新 一条旧的记录从而完成更新操作;
-
你可以通过 先查询到记录的时间戳来删除 指定时间戳的一条记录;
Insert 与 Import
为了支持高效的插入操作(Insert),对于同一张表, TDengine要求新插入的记录的时间戳大于表中的最后一条记录,否则记录被丢弃。TDengine所有表以时间戳为主键,这个的意思即要求记录以主键序顺序插入。该要求使得Insert操作可以通过追加写最后一个数据块的方式高效完成,而不需要考虑乱序插入时的排序与数据块合并等问题。如果你确实存在需要往表里写历史数据(时间戳小于表中的最后一条记录的时间戳)的情况,那么TDengine提供了另一个Import操作支持该需求,当然Import操作会比高频的 Insert操作低效一些。
TDengine的最佳实践中建议,为每一个独立的产生数据的IOT设备建立一张独立的表,这样即使不同设备之间存在时钟不同步或者到达服务器的网络延时不同的情况,同一张表内的数据仍然可以保证是顺序写的(源自同一设备)。
考虑车联网的场景,当一辆车停在无网络的地下车库一段时间没有上报数据时,当车辆再次联网后开始上报数据时,我们期望车辆先将最新时刻的状态数据上报上来,以便用户可以及时的了解车辆的最新实时状态及故障警报,而后再将断网期间没有上报的历史数据补发上传。这样的单个设备的乱序上报在车联网的场景下,相对于其他有固定联网条件的物联网设备会更常见一些。
数据的一致性
Eric Brewer提出过经典的CAP理论:一个分布式数据存储系统最多只能同时满足一致性(Consistency),可用性(Availability),分区容错性(Partition tolerance)中的两点:
-
一致性:每一个读操作(无论落在哪个节点)都可以得到一个最新写的结果或者明确的错误响应;
-
可用性:每一个读写操作都可以得到一个非错误的响应(但不保证读到的是最新写的结果);
-
分区容错性:无论节点间的网络问题导致了多少消息丢失或者延迟到达,系统都可以继续运转;
通俗的理解就是:分布式系统通过冗余节点来提高可用性,而冗余节点引入了数据的同步和一致性问题,如果A,B两个冗余节点之间发生了网络分区(导致同步失败),那么系统的设计者需要做一个选择,保证可用性(用不一致的数据提供服务),还是保证数据一致性(中止服务避免不一致的数据写入)。
由于网络传输中分区问题的普遍存在(比如机房交换机故障,光缆被割断等),分布式存储系统普遍会支持分区容错性(P)。不同的分布式存储系统,针对其存储的业务数据的重要性,在当网络分区出现的时候优先选择可用性(AP)还是一致性(CP)上会有不同的决策。比如Google的MegaStore,微信的PaxosStore被设计成强一致性的系统,而Cassandra支持配置成不同级别的数据一致性,Master-Slave方式同步的Redis并不保证能及时从Slave节点读到最新写入的数据。
从TDengine的文档中了解到,对于存储时间序列数据的vnode节点,TDengine企业版使用了master/slave异步写的方式来将数据同步到slave。而对于存储数据库元数据的管理节点mnode,TDengine采用强一致性的方式进行数据同步。可以理解在IOT场景下对于不断产生的时间序列数据,可以接受一定程度的数据点不一致,而对于创建表/修改表这样的操作产生的数据库元数据,在集群中则务必保证各个mnode节点上的数据保持强一致性。
Everything is about tradeoff
TDengine在物联网的场景下以牺牲部分功能支持的代价换来了超过10倍的性能提升。区别于其他时序数据库底层使用基于树的存储引擎数据结构(InfluxDB使用Time-Structured Merge Tree),TDengine基于 顺序表结构的存储,追加写的插入,二分查找的查询,结构化的定长数据,预计算的聚合结果等优化 大大提升了时序数据存储的读写性能。当前完整的TDengine开源代码近13w行,本文仅选取了项目的若干点进行探讨,TDengine在工程方面也有不少值得借鉴的地方。
在商业模式上,TDengine 选择了与InfluxDB同样的 开 源 单机版,销售集群版的路线,作为国内少有的热门开源项目( github 开源一周 近5千 Star)后续发展值得关注。
附InfluxDB三年前关于闭源其集群功能的一些考虑:
